llama2 in Rust, with Metal and Rayon
For the up date version of the post see my llama2-rs on GitHub.
llama2-rs
This is a rewrite of llama2.c to Rust and Apple M2 Metal GPU, with a bit of Rayon. This code is just for learning purposes, it is not maintained. Below are the learnings.
Prerequisites
You need tokenizer.bin from the original llama2.c repo, also you need the
TinyStories model, or a full llama2 7B model. See
llama2.c on how to download and convert the model.
Diagrams
Here are some diagrams that I draw along the implementation to understand what the code actually does. Those diagrams later helped me to figure which matrix multiplications can be run independently.
High level
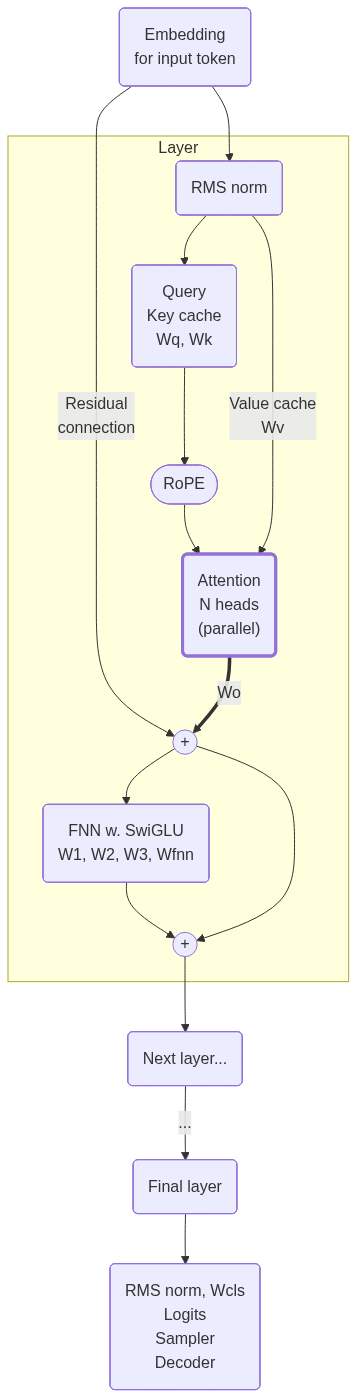
Detailed
The detailed flow diagram based directly on the code:
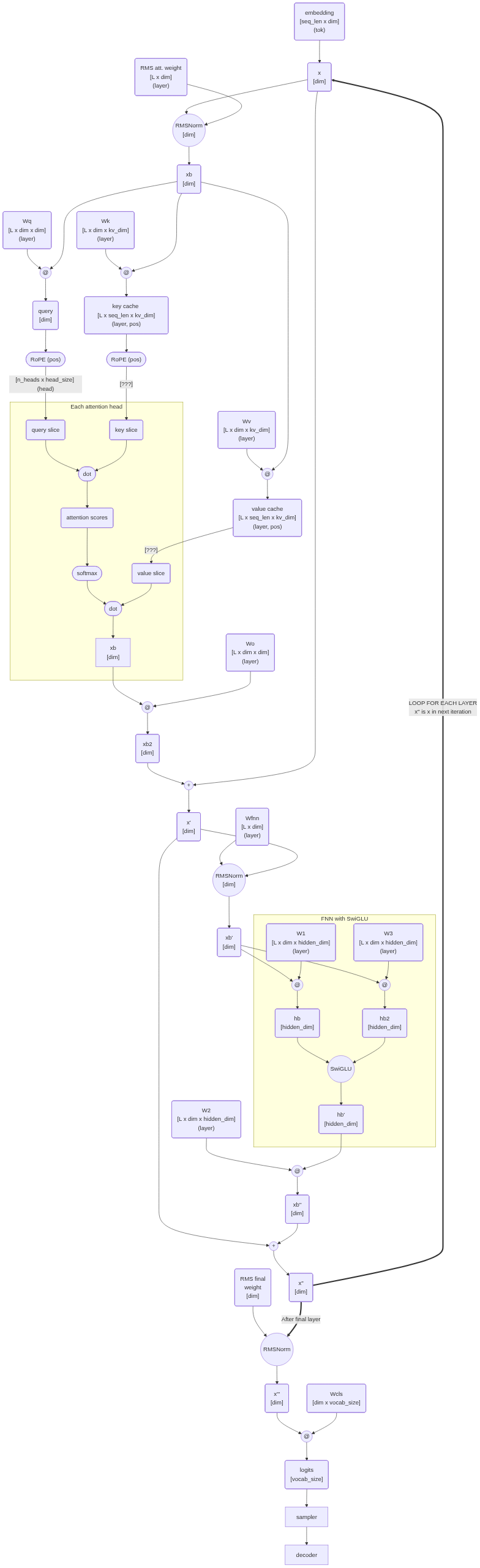
Learnings
Rust:
-
Using Rust type (like
TokenIdinstead ofusize) helps to understand the code. -
Use
assert!a lot. When you have matrices or vectors that assume some sizing, add assertions to find the bugs early. Most of this code deals with buffers of different sizes, and the sizing is often the only thing that you can assume. An assertion firing was several times the only thing that hinted me that I confused dimensions. -
If you don’t keep Mmap object alive, it will be dropped and accessing the pointed data will result in a segfault.
-
Use
cargo objdump --bin llama2-rs -- -d -S ./target/debug/llama2-rsto see the assembly output, e.g. to see if the code is vectorised. -
You can check if the generated code uses SIMD and vectorization by inspecting disassembled code, and looking for SIMD instructions (that start with “f” like
fmul):make objdump-llama | egrep '^000| \tf' | grep llama2_rs -A1 0000000100005494 <_llama2_rs::main::h9ba2e6463cb6eab5>: 100005710: 1e202008 fcmp s0, #0.0
-
Just slapping
rayonandpar_itertremendously speeds up the code. -
Use
RAYON_NUM_THREADS=1for sequential execution, good for debugging.
Metal:
-
Just slapping GPU at the problem (this problem at least) will not make it magically faster.
-
I didn’t see much difference in performance when using shared or private GPU memory buffers. Maybe it’s because of specific access patterns of the program.
Float16:
-
65520 is already an infinity in f16.
-
Apple M2 Metal does not support matrix multiplication on BFloat16:
MPSMatrixMultiplication.mm:3260: failed assertion `Input data type must be one of MPSDataTypeFloat32, MPSDataTypeFloat16, MPSDataTypeInt8, or MPSDataTypeInt16.' - Also, you cannot multiply int and float in a single matmul:
MPSMatrixMultiplication.mm:3250: failed assertion `Mixed input matrix multiplication is only supported when A.dataType == C.dataType == MPSDataTypeFloat32 and B.dataTyp e == MPSDataTypeFloat16.' -
When doing matmul on f16, you need the output to be f32, otherwise the output will corrupt. Fortunately, Metal supports matmul for f16 at input and f32 at output.
- Using f16 was slower for TinyStories than f32.
Other:
-
ChatGPT was very useful in learning
lldbcommands. -
mermaid is an absolutely fantastic tool for diagrams.
-
Monitor if you memory does not start to swap , with
sysctl vm.swapusageor Activity Monitor. If mem swaps, the computation will instantly become dog slow. -
Apple’s Instruments is useful to see GPU utilization, flamegraphs, etc. You need cargo instruments. See Makefile and instruments-tinystories there on how to use that. Mind that you need debug symbols in the binary, with
debug = truein Cargo.toml
Benchmarking Rayon
I didn’t run very rigorous benchmarks, rather run inference on TinyStories 42M model, and also on llama2 7B model.
-
34 tok/s - TinyStories, no parallelization, no rayon, sequential as it can be. commit
-
27 tok/s - using naively par_bridge commit. Slapping naively
par_bridgeis slower that sequential execution on a single code. I suppose it’s the overhead of coordination of those small work chunks. -
132 tok/s - with naive use of rayon and par_iter. commit. Rayon is awesome!
We can further tweak Rayon to take larger chunks of work, to spend less on
coordination. Here are the results of modifying with_min_len
parameter:
- 1 - 132 tok/s
- 5 - 146 tok/s
- 10 - 153 tok/s
- 15 - 154 tok/s - best
with_min_lenvalue. commit - 20 - 150 tok/s
- 40 - 142 tok/s
- 70 - 115 tok/s
- 150 - 93 tok/s
FTR, the machine I use has available parallelism is 12 (8 performance and 4 efficiency cores).
Metal
I use Apple Metal to interface GPU and run matrix multiplciation on GPU. Examples:
- metal_add.rs implements a simple addition in GPU using a shared memory buffer.
- metal_matmul.rs runs matrix multiplication on GPU.
Caveat: for TinyStories the benchamrks are in tok/s (higher better) and for llama it’s s/tok (lower bertter).
Running llama2 (make run-napalm) with matmul naively computed in GPU (shared
memory buffers, Metal native matmul) yields ~20% GPU utilization, and ~60
s/tok. For CPU with Rayon, it’s ~20 sec per token. So, just throwing naively
GPU at the problem didn’t help at all.
Initially all the models were in f32, I later cast the models to f16 (1/2 mem usage). Surprisingly, using f16 made TinyStories inference slower (12.8 tok/s with f16, drop from 16 tok/s with f32).
I played with shared GPU memory and private GPU memory. In theory private mem should work faster since there there is no cache synchronization with CPU. But, when I moved the weights from shared mem to private mem, the inference was somewhat slower: I got 4.26 ms per matrix multiplication with shared buffer, and 4.52 ms for private buffer - commit. Maybe it was because matrix W was in private mem and vector X was in shared mem?
I optimised the code to not wait for GPU result when I don’t need to (pipelining). That is, I push commands to Metal’s command buffer, those commands run in parallel to CPU, and I wait (blocking) for the result when I need it. With the pipelined execution on GPU I got 18.5 tok/s on TinyStories and 3.5 s/tok on llama2. Note that for TinyStories, it was way faster to run it with Rayon and CPUs. For llama2, it’s faster to run it on GPU.
Materials
- From Multi-Head to Latent Attention: The Evolution of Attention Mechanisms
- Positional Embeddings in Transformers: A Math Guide to RoPE & ALiBi
- LLM Embeddings Explained: A Visual and Intuitive Guide
- SwiGLU
- Apple Metal:
Where to go from here
Some next ideas to further improve the code
- Support llama3
- Use LLM.int8 quantization. Here post about emergent features and this post on HuggingFace